Taming the Chaos: Building a Custom File Format Toolkit
Imagine situation: you are a big company chasing the AI trends, and you want to do unimaginable amount of data analysis, but all of your data is encoded in files, which none of the existing programs cannot read properly. That is the place, where I should come in and solve these problems.
Hello, my name is Nikolai Dorofeev and here I would like to share my experience in systemizing proprietary standards and implementing a toolkit for it.
Prehistory
Some time before the main events described in this article, I was asked to update one small detail in a large proprietary file. It was something like “Change property ID from A to B in all occurrences”. I, professional JSON Ops, obviously thought, that it is not a big deal, I can just read the file using a special deserialization function, make required changes and save changed objects back into the file. Therefore, I asked for the parser, and that was the most naive question in my life.

It appeared, that some very clunky ways existed, however there were no solutions for extraction of meaningful structures from our files. It was a start of disappointment in this world, but the task was completed by a regular-expressions-like approach.
Understanding the entity encoded into the files
There is a reason why all the crucial data is stored in the surprising new format - it is used for execution of core business scenarios. And this information was 80% enough for extracting our core business entity.
There is another incredibly convenient thing - these files are stored as CSV files, so I could open it in spreadsheet software.

It was no CSV file I had ever met before. There definitely are some tables, but it looked like the files stored not a single but several tables with metadata for each “scenario” as I could see from markers. After some time I figured out, that these “scenarios” describe scripts to simulate user’s activity in a system, and it has the following structure:
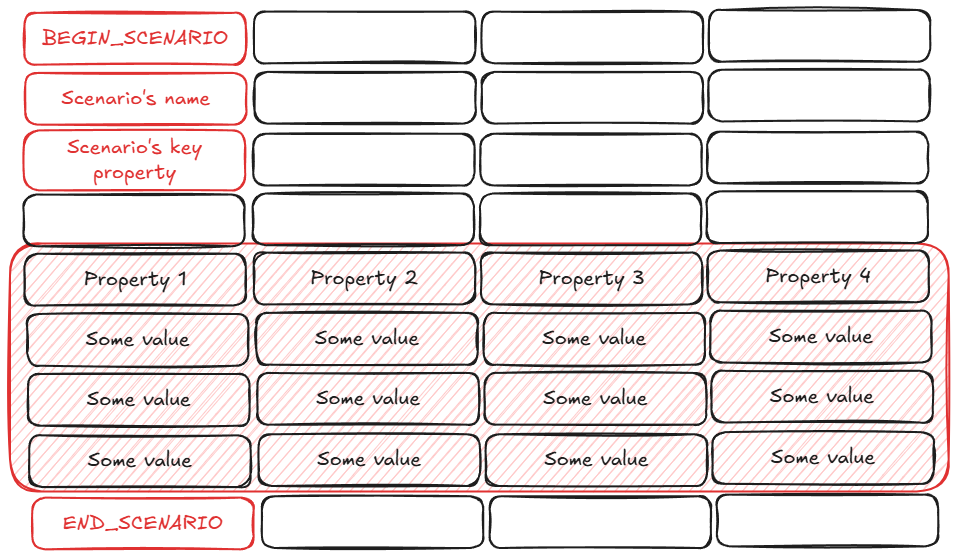
- Begin indicator of the scenario - specific value in the first cell of a row
- Scenario’s name - text in the cell right under the beginning indicator
- Domain-specific scenario’s property value - text in the cell right under the name cell
- Empty row - just for aesthetic when displaying in a spreadsheet software
- Table of steps describing user’s behavior in the system
- First line - columns’ names
- Following lines - steps’ values
- End indicator - specific value in the first cell of a row
It appeared, that this brand-new format was intentionally built on top of CSV to make it more visually interpretable and give users an opportunity to edit it with well-known spreadsheet software. Further, I will call this format “Super CSV”, as it stores many tables in a single file, while classic CSV keeps only one table inside.
It looked quite simple and good enough to make a first prototype, so it was time to do some coding.
Changing coding approach
I am not a type of people, who writes everything with my own hands just because they cannot read and understand others’ code. I am smart, I need to simply build a convenient abstraction over already existing code.
So. I found the code for my basis. And building something over it was not an optimal solution for several reasons. Firstly, it supported only read-transform-write operations altogether, therefore I could not these features separately. Secondly, it did not use memory in optimal way - the whole file stored in raw format even if I needed only the first entity from it. Thirdly, it was already overcomplicated - team of four analytics was not able to understand this solution in three months.
Regardless of the listed disadvantages, I was able to pick the most useful interpretation part and copy it to the fresh file with the future toolkit. It was not building an abstraction over existing logic, but it still was reused logic.
For some reason, the original solution read a file into pieces of raw data, what limited a lot of capabilities for analysis and modification. On place of this mistake, I built a good old data class storing a structured data. Originally it included “name” field, getter for the important property and the steps table in a form of Pandas data frame (the code base happened to be Python code). However, later I had to write my custom table implementation to prevent users’ skill issue.
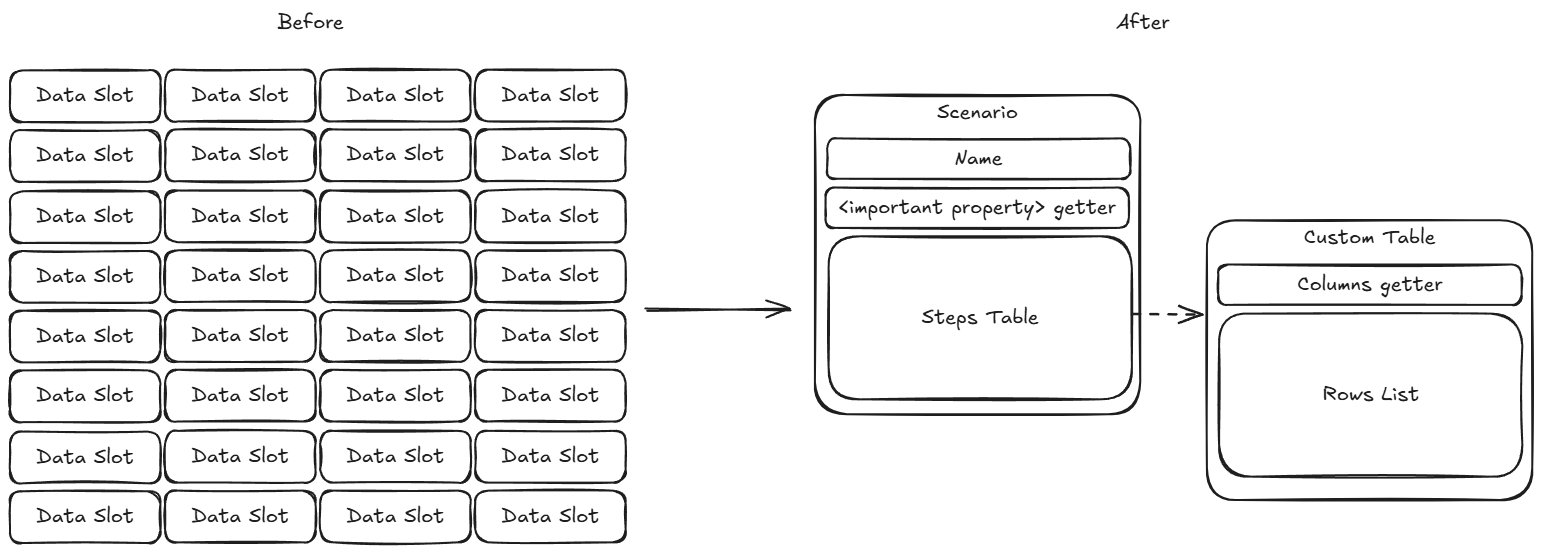
The most convenient solution is the most familiar solution, and the existing one looked completely strange in Python ecosystem. It was just built around the concept of callbacks, which creates a lot of barriers for a Python user. It is not possible to annotate a whole function with one imported type to ensure its correctness before passing as a parameter and Python does not allow creation of multiline lambda function, if we want to define the callback directly inside a function call. The only way, that somehow works is to create a class, where method should be rewritten, but who wants to create 10 classes for a single script?
Looking for an inspiration, I found “csv” module. CSV format is conceptually close to Super CSV - both store a sequence of some data. It is also well-known and relatively simple. I decided to go with this approach. As a result, time required to understand the tool reduced from 3 months to 5 minutes.
# Before
from lib import SuperCsvManager, Scenario
scenarios = []
current_scenario = None
def on_scenario_name_read(name):
nonlocal current_scenario
current_scenario = Scenario(name=name, steps=[])
scenarios.append(current_scenario)
def on_scenario_step_read(step):
current_scenario.steps.append(step)
SuperCsvManager.read_file(file,
on_scenario_name_read=on_scenario_name_read,
on_scenario_step_read=on_scenario_step_read)
# =========================================
# After
from lib import SuperCsvReader
scenarios = list(SuperCsvReader(file))
Do not underestimate users
Remember the clear and understandable file layout given at the beginning? Forget it, here is the real layout:
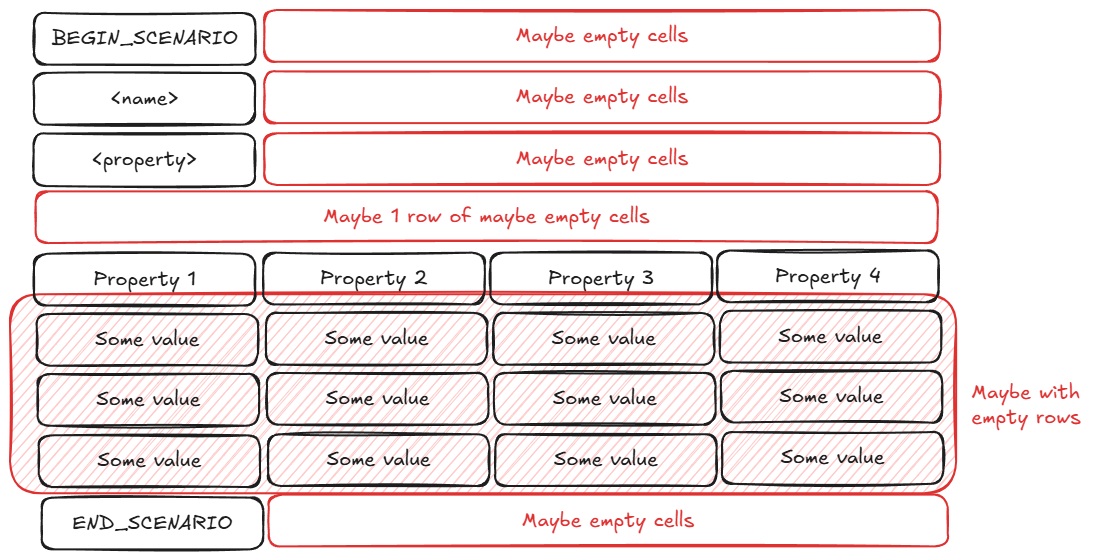
As Super CSV can be opened and edited in a spreadsheet software, users can do whatever they want, because Excel does not know about our own restrictions. That is why it was decided to make Super CSV parser extremely tolerant to any kind of mistakes, they will be automatically fixed if possible.
The most popular way of using of free cells was leaving the comments, and it was hurtless except 1 particular slot. Parser thought, that the first line with data after the property slot is the header of a steps table. However, a cell between the property and the table was also used for a comment.
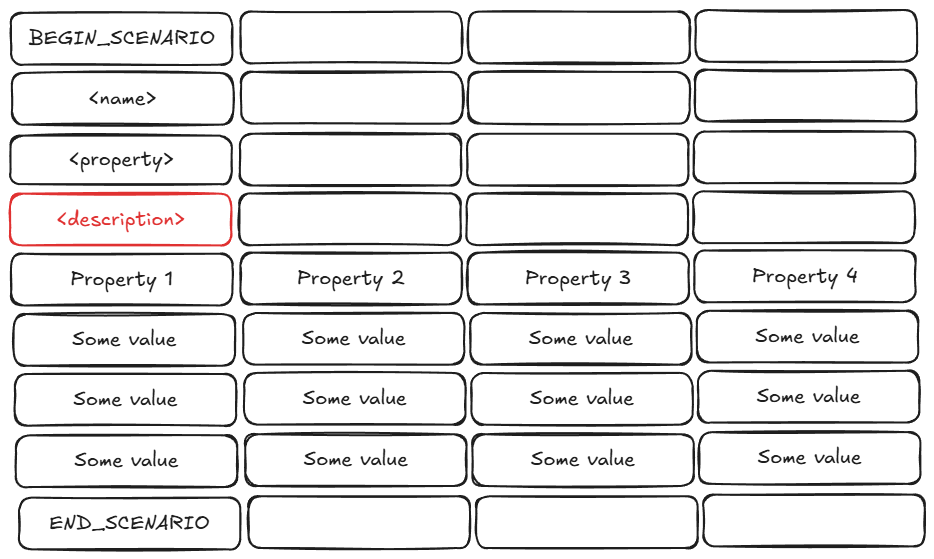
A first idea was to reformat the problematic files, but it appeared, that there were tons of them. That way, I had no other options rather than accept a new description slot for the Super CSV standard and add corresponding logic into the toolkit.
Key Takeaways
Of course, I also implemented a Super CSV writer, adapted these classes for Python-specific resource management, implemented a query system for the custom tables, and so on. Even though these stories are not so interesting, because they were not broke by users.
From these experiences and challenges, several key lessons emerged about designing file format tools:
- Custom file formats require careful consideration of user behavior and real-world usage patterns
- Building on familiar concepts (like CSV) makes tools more accessible and easier to understand
- Simple, intuitive APIs are preferable to complex callback-based approaches
- Parser tolerance is essential when users can modify files through spreadsheet software
- Standards may need to evolve based on how users actually use the format
The journey from a complex, callback-based system to an intuitive file format toolkit demonstrates the importance of user-centric design in technical solutions.